Devtools and Reverse Engineering
The first step to web scraping is to understand how the target website is working. This step is often called reverse engineering and is a crucial part of any web scraping project.
Every modern web browser comes with development suite of tools which can be used to debug and inspect web pages. This tool suite is called devtools and is a powerful tool for reverse engineering and vital in web scraping development.
In this section, we'll have a quick overview and introduction to this tool suite though it's best to give it a shot and experiment yourself.
Introduction
The devtools console can be usually launched using F12 key (in ) or alternatively by selecting "inspect" option when right clicking on the page.
The tool suite is divided into several tabs, each representing a different tool. When it comes to web scraping we're mostly interested in the Element and the Network tabs:
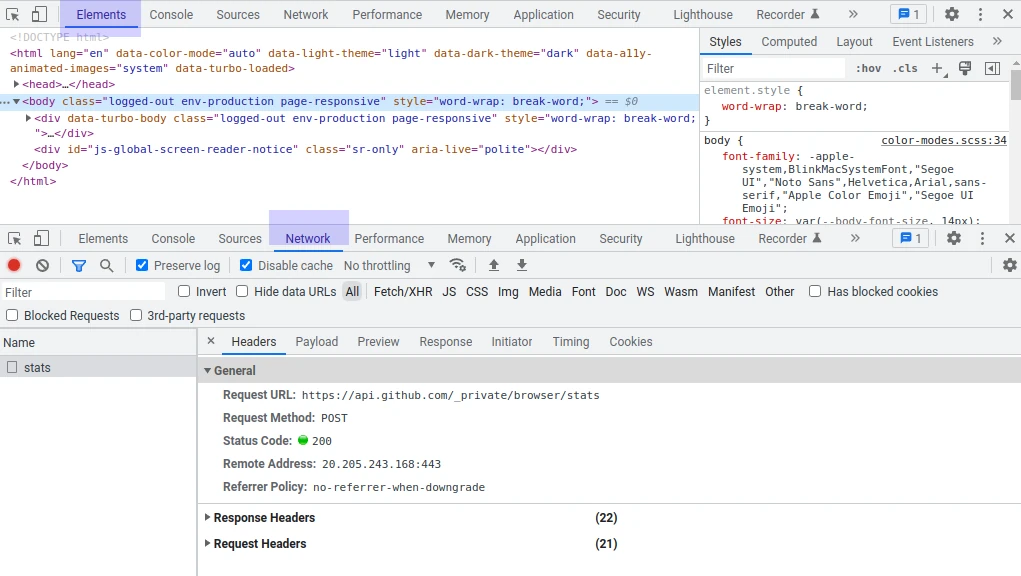
Network Tab
The Network tab show us all of the HTTP connections our browser is performing on this page. Ranging from image downloads to secret background requests that are used to generate dynamic data.
When web scraping, we can use this tool to find hidden APIs the website is using to generate dynamic data. Let's take a look at an example Networks tab and some tips on how to use it:
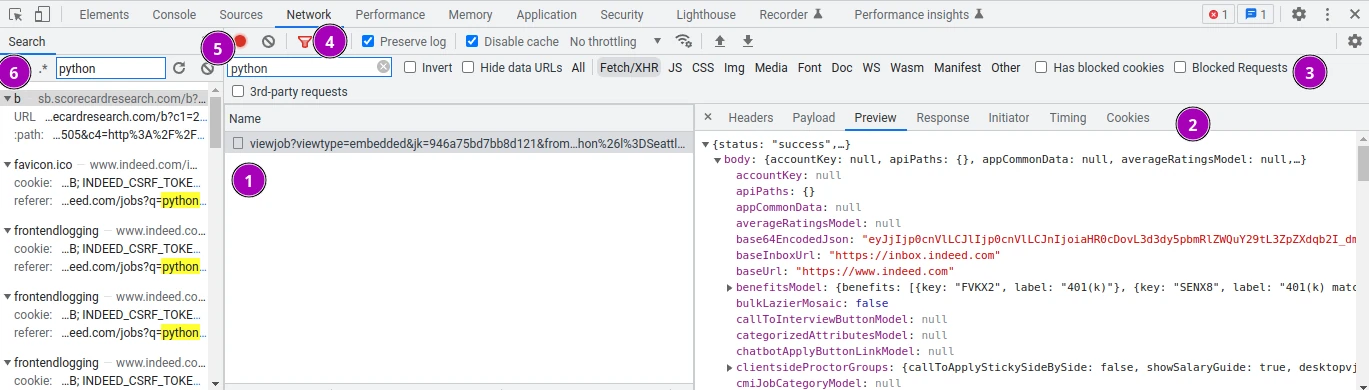
- That's where all of the requests are listed.
- Clicking on request we can examine its details from what data was sent and what data was received.
- We can filter requests based by type.
The XHR tab captures background requests and the doc tab HTML documents - Tip: make sure to check Preserve Log and Disable Cache to avoid missing out on data
- We can search requests by URL
- We can also search requests by any other part like request or response body (opened with Ctrl+F) This option can be opened with Ctrl+F and is very useful for finding background requests.
Curlstring Conversion
Devtool requests can easily be converted to web scraping requests by right-clicking individual request and selecting Copy -> Copy as cURL option:
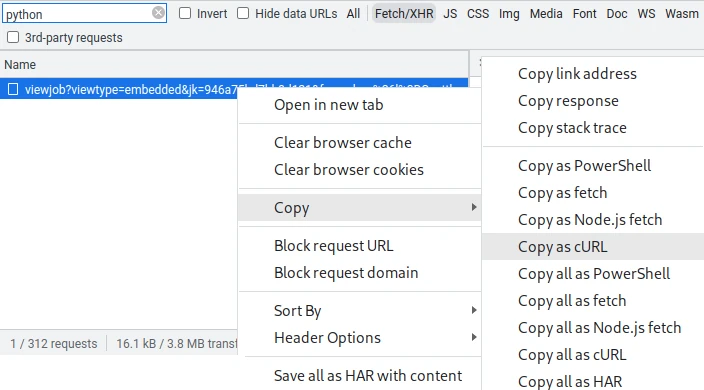
Then the cURL string can be input into various curl converters like this one powered by curlconverter - take a look at the built-in examples below:
import requests
response = requests.get('http://example.com')Converted requests should still be manually updated with headers, cookies etc. and can often miss important details that would make the request invalid.
Elements Tab
The Elements tab shows us the current HTML structure of the website.
This shows the fully rendered HTML tree which is likely to differ from what the web scraper sees unless you are using browser automation for scraping. For more see dynamic javascript scraping section.
When web scraping, we can use this tool to build our scraper's parsing logic and for general understanding of the websites structure.
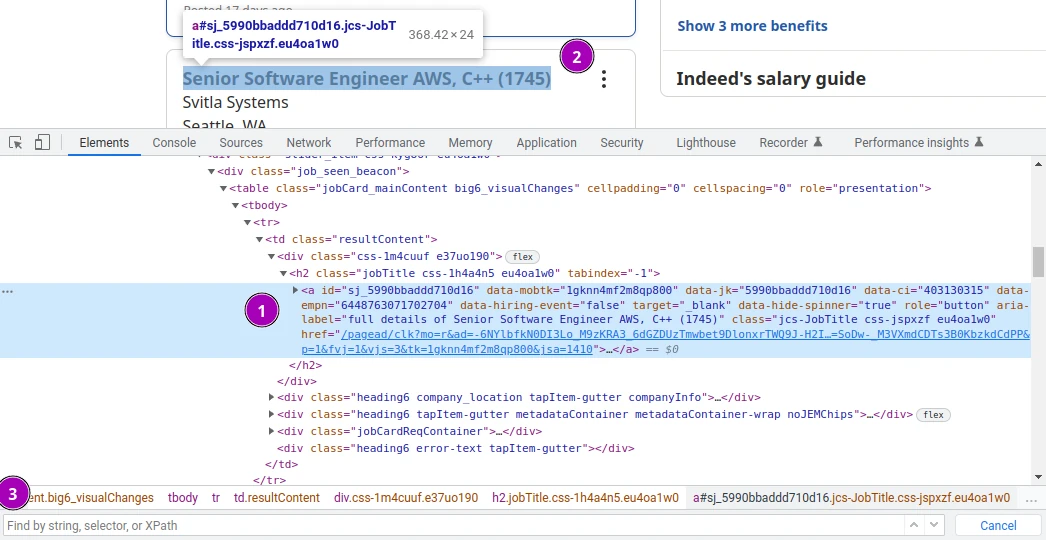
- The navigation tree where we can see and interact with all of the HTML elements.
- The selected elements will be highlighted on the page.
- We can search for elements by CSS selectors, XPath or just text.
Other
There are a lot of other tools in the devtools suite that ocassionally come in handy when developing web scrapers.
The Console tab can be used to explore javascript variables. This can be useful when scraping javascript powered websites:
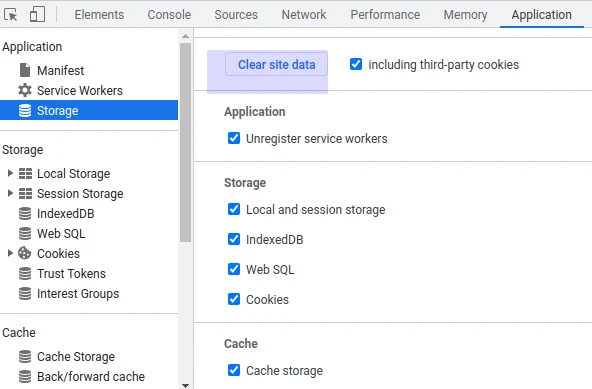
The Application tab can be used to explore local data storage and delete current session details like cookies:
Extensions
The developer tools can be extended by community plugins that assist with reverse engineering specific technologies or frameworks:
| extension | description |
|---|---|
| GraphQL Network Inspector | Easier to follow graphQL requests |
| React Developer Tools | For reverse engineering React websites |
| React Developer Tools | For reverse engineering React websites |
| Angular DevTools | For reverse engineering Angular websites |
| Vue.js DevTools | For reverse engineering Vue websites |